导语
做MLND项目时一直没有搞懂如何选择SVM参数,因此监督学习总结第一篇献给SVM,希望能带领大家稍稍深入理解SVM
本篇主要解决一下问题:
- SVM有哪几类?各自解决的问题是什么?
- 什么是支持向量?
- 如何确定最大间隔超平面?
- 如何应对线性不可分的情况?
- 什么是核(kernel)?
- 有哪些核kernel?优缺点和使用条件是什么?
- 有哪些超参数?调节各个超参数的作用是什么?
- 为什么说SVM适合高维数据?
线性可分SVM
SVM其实是一个包含了很多个监督算法的集合,用于解决分类问题,回归问题和孤立点检测(outlier detection)。
SVM最基础的模型是线性可分支持向量机,用于训练集线性可分情况下的二类分类。核心思路是,尝试寻找一条远离所有分类的线,这条线被称为最大间隔超平面(maximum-margin hyperplane),如下图所示

分隔超平面Hyperplane

上图中将数据分隔开来的直线或面就是分隔超平面(separating hyperplane)。分隔超平面也就是决策边界。在二维数据点上分隔超平面就是一条线,3维中分隔超平面就是一个平面。依次类推,分隔超平面的维数总是比数据集的维度少一维。
对于二类线性可分的数据集,分隔线可以有无数种画法,但是哪一条是最好的?在此我们定义数据点到超平面的距离为间隔(margin)。并且我们希望在离超平面最近的点(即支持向量)之间的间隔最大。也就是说,间隔最大化的意义在于,不仅将正负实例点分开,而且对最难分类的实例点(离超平面最近的点)也要有足够的确信度将它们分开。
支持向量Support Vector
线性可分情况下,训练集的样本点与分割超平面距离最近的点称为支持向量(support vector)。
在决定超平面时只有支持向量起作用,而其他实例点不起作用。正是由于支持向量在确定分离超平面中起着决定作用,所以将这种分类模型称为支持向量机。

最大间隔
在二类分隔问题中,我们用$y=+1$ 表示正类,$y=-1$表示负类。即对所有的样本点$(x_i,y_i)$ ,$y_i\in {-1,1}$ 。分隔超平面的形式写为$w^Tx + b$ ,其中$w$ 是向量,$b$ 是截距。
于是线性分类器可写为:
$f(x) = sign(w^T + b)$
我们的目标是找出分类器定义中的$w$和$b$ ,为此,我们首先需要找到具有最小间隔的数据点,即支持向量。一旦找到支持向量,我们就需要让间隔最大化
但是我们如何表示样本点与超平面的间隔?这就引出了函数间隔和几何间隔的问题
函数间隔functional margin
对于给定训练集和超平面$(w,b)$ ,定义超平面和样本点$(x_i, y_i)$的函数间隔为
$\hat{\gamma_i} = y_i(w^Tx_i + b)$
同时定义所有样本点函数间隔的最小值为
$\hat{\gamma} = min\ \hat{\gamma_i}, i=1,\dots N$
这时我们发现成比例改变$w$和$b$ 时,例如改为$2w$和$2b$时,超平面没有改变,但是函数间隔却成了原来的2倍。
如果需要让间隔保持确定,我们可以对$w$加一些约束,使其规范化,这就是几何间隔
几何间隔geometric margin
对于给定训练集和超平面$(w,b)$ ,定义超平面和样本点$(x_i, y_i)$的几何间隔为
$\hat{\gamma_i} = y_i(\frac{w^Tx_i + b}{||w||})$
同时定义所有样本点函数间隔的最小值为
$\hat{\gamma} = min\ \hat{\gamma_i}, i=1,\dots N$
几何间隔即点到分隔超平面的距离,当点$(x_i,y_i)$为正类时,类标记$y_i=+1$ 。几何间隔为
$\hat{\gamma_i} = \frac{w^Tx_i + b}{||w||} $
如果点在超平面负的一侧,则点到超平面的距离为
$\hat{\gamma_i} =- \frac{w^Tx_i + b}{||w||} $
如果$||w||=1$,那么函数间隔和几何间隔相等
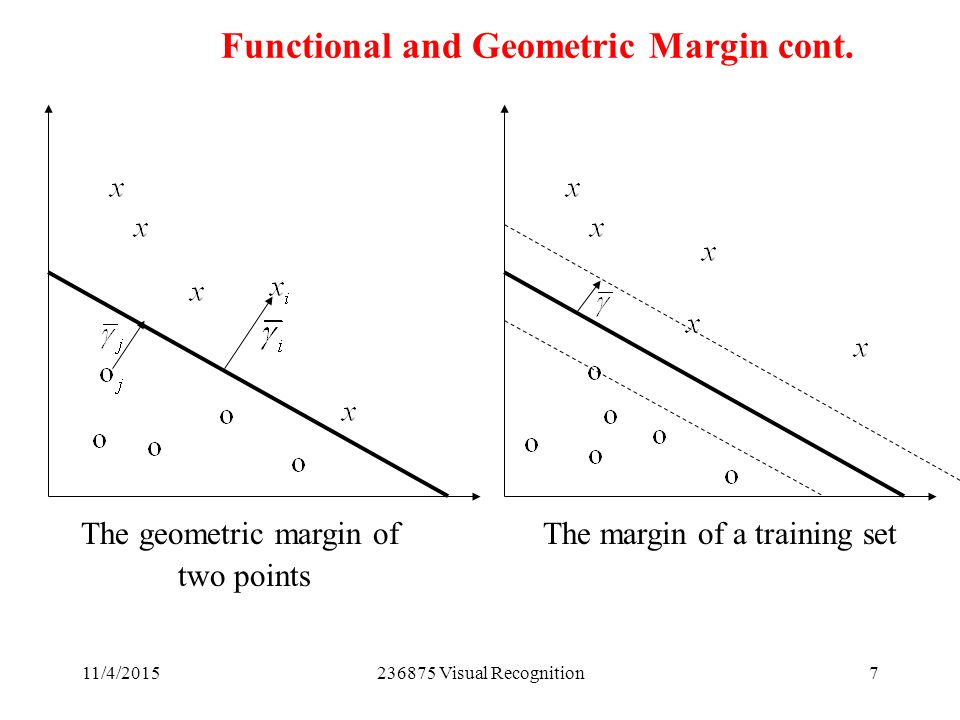
间隔最大化
于是我们的问题细化为求一个几何间隔最大的超平面问题。
max $\gamma$
s.t.
即对于超平面$(w,b)$最大化几何间隔$\gamma$ ,同时每个样本点对超平面的距离都大于等于$\gamma$ 。s.t 是subject to的缩写,表示约束条件。
将其改写为函数间隔$\hat{\gamma}$
max
s.t.
由于规范项的存在,函数间隔的取值并不影响最优化问题的解,为了计算方便,我们可以让函数间隔取$\hat{\gamma} = 1$ 。并且最大化$\frac{1}{||w||}$与最小化$\frac{1}{2}||w||^2$ 是等价的。
最终间隔最大化问题转换为:
最小化 $\frac{1}{2}||w||^2$ ,并且
对于所有$(x_i,y_i)$,
对偶问题优化
上述的优化问题是一个带约束的条件的优化问题。对于此类优化问题,有一个非常著名的求解方法,即拉格朗日乘子法Lagrangian Multipilier 。
对此,对每一个不等式约束我们可以构建拉格朗日函数为:
为了得到问题的对偶(dual)形式。我们需要首先先求$L(w,b,x)$对w,b的极小:
即将拉格朗日函数分别对w,b分别求偏导并令其等于0.
得
再将其代回拉格朗日函数得:
得
由此,我们问题进一步转化为对偶优化问题:
求$L(w,b,\alpha)$对$\alpha$ 的极大即
说了这么多求出$\alpha$ 有什么用呢?因为满足KKT条件下,对偶最优化问题的解$\alpha^ = (\alpha_1^,…\alpha_N^)$ 与原始最优问题(找到分隔最佳的超平面$(w^,b^*)$) 有下列关系:
因此分隔超平面可以写成
其中$\langle x_i,x \rangle$ 表示向量内积,等同于$x_i^Tx$
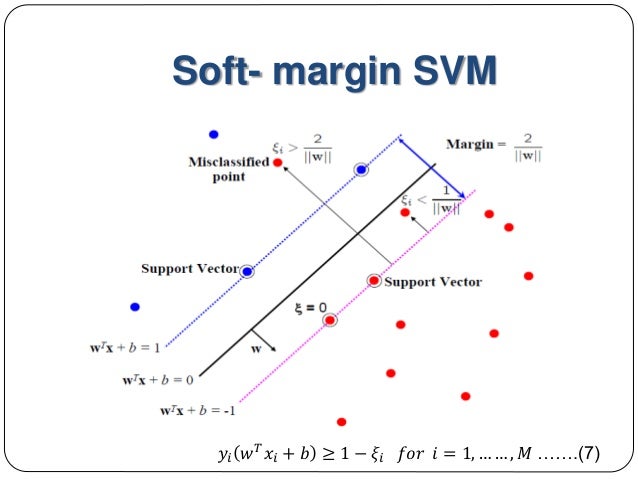
软间隔Soft Margin
上述讨论都是在数据点线性可分情况下进行的。我们将上述间隔称为硬间隔。
现实生活中,有很多数据是没有办法一刀切开的。如下图所示,无论分隔线放在哪里,都不可能将蓝点和红点完全分开。即无法满足函数间隔大于等于1的约束条件。这时我们该如何定义最大间隔并找出对偶优化问题呢?
松弛变量Slack Variable
为了解决这个问题,我们引入一个松弛变量$\xi\ge 0$ ,使函数间隔加上松弛变量大于等于1。这样约束条件变为
松弛变量的引入常常是为了便于在更大的可行域内求解。若为0,则收敛到原有状态,若大于零,则约束松弛。即上述线性可分支持向量机是线性支持向量机的一种特例:松弛变量$\xi=0$
惩罚参数C
引入松弛变量后必然会对优化产生影响,我们对松弛变量加上一个惩罚(penalty)参数C,目标函数调整为
C的作用在于希望使$||w||$ 尽量小(即间隔尽量大),同时使大多数样本点的函数间隔大于1(即误分类的个数尽量少)。当C比较大时,对误分类的惩罚增大;当C小时,对误分类的惩罚减小。
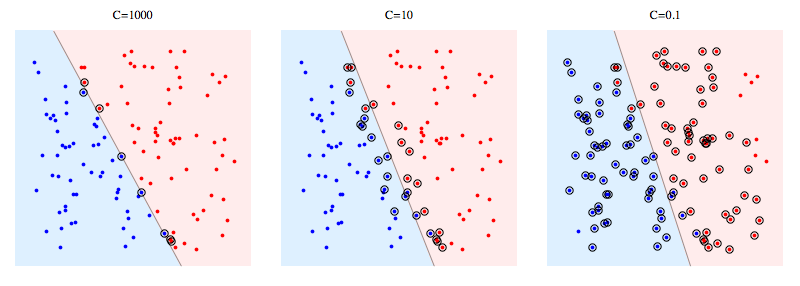
上图中被圆圈圈住的点是不同C值下的支持向量。可以看出,C的减小使得分类器为了获得更好的泛化能力而牺牲样本点线性分隔性。反过来说,C值越大,分类器就越不愿意允许分类错误(“离群点”)。如果C值太大,分类器就会竭尽全力地在训练数据上少犯错误,而实际上这是不可能/没有意义的,于是就造成过拟合。
对偶问题优化
经过上面一番探讨,线性支持向量机的学习问题变为:
相应的拉格朗日函数为
其中$\alpha_i$和$r_i$ 均为拉格朗日乘子($\ge 0$)。如之前推导一般,首先求函数对$w,b$的导数,然后回代入函数。得:
非线性支持向量机
软间隔解决依然是近似线性可分的数据集,而一些数据集则是完全非线性可分的(或者有噪声的)。如下图所示
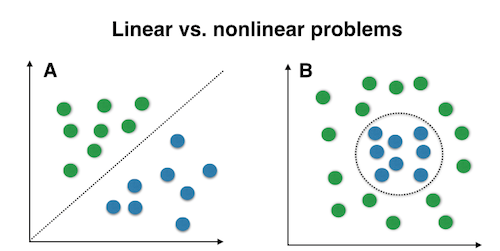
原始数据集虽然非线性可分,但是我们可以首先通过一系列变换将数据变得线性可分,即核技巧(kernel trick)。
核kernel
核的作用就是通过一个非线性变换将输入空间(欧氏空间$R^n$)对应到一个特征空间。这样线性支持向量机便可以在这个特征空间寻找一个超平面完成分类问题。

我们用$K(x_i, x_j)$表示核函数,并且
其中$\phi(x)$ 表示输入空间到特征空间的映射。

这是不是意味着我们需要先定义映射关系呢?并不是的,映射常常导致特征变多(维数增多)。而且非常不容易计算。
核函数能简化映射空间中的内积运算,避开了直接在高维空间中进行计算。给定核函数下,特征空间可以取不同的映射。可以说核函数是特征空间的隐式映射。当映射函数是非线性时,学习到的含有核函数的支持向量机即为非线性分类器。
对偶问题优化
引入核函数后(核函数替代内积),优化问题变为:
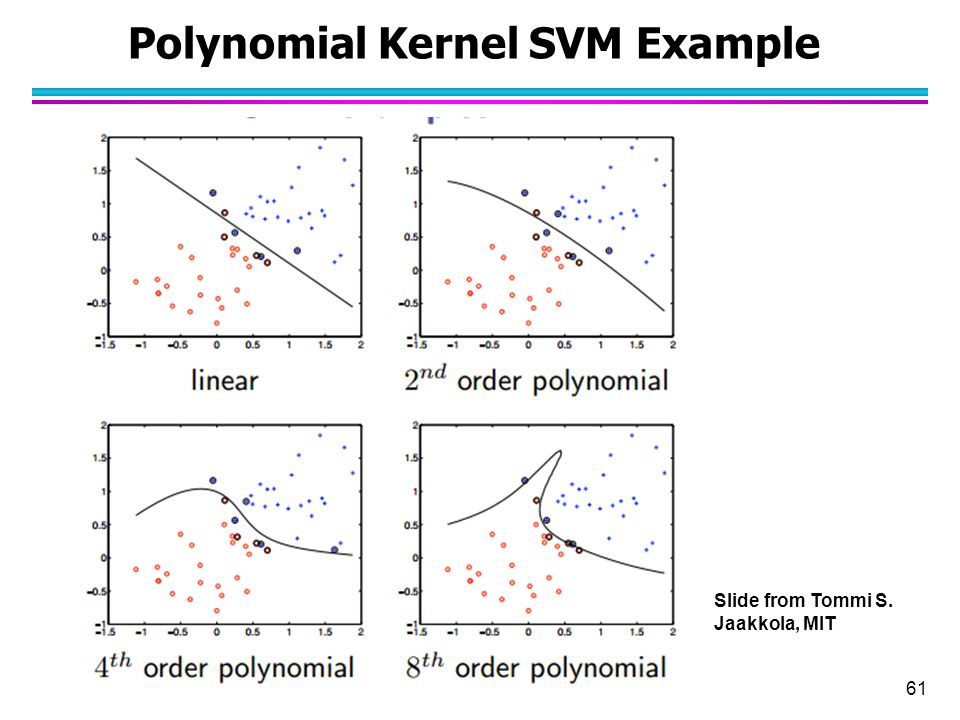
常用的核(kernel)
不同的核有不同的效果,什么都不用时也可以视为核的一种(线性核)。当然不是随便定义一个函数就可以作为核的。核函数必须是正定核函数(positive definite kernel function),在此就不证明了。这里介绍几个常用的核函数。
线性核(Linear)
多项式核(Polynomial)
该核的对应的映射空间维度是$\binom{m+d}{d}$ ,其中m是原始空间的维度
高斯核(Gaussian)

不同$\sigma$ 下的高斯函数,从左到右$\sigma^2$ 依次减小
高斯核更常用的名字是径向基函数核(radial basis function kernel),即rbf核。大多数库径向基核是默认的核。
SVM的核还有很多比如,字符串核(string kernel function),Sigmoid核等等。可以通过交叉验证实验不同核与参数的效果,缺点就是处理大数据集时会比较慢。
SVM优缺点
最后总结一下SVM的优缺点
优点
- 因为核技巧,处理高维数据很有效
- SVM本质是一个凸优化问题,没有局部最小,并且有相应高效的算法(SMO)
- 只需要用到训练集的一部分(支持向量),所以空间效率高
- 多样性:决策函数可用不同核函数,并且可以自定义
缺点
- 当特征维数远大于样本数时效果不好
- 训练和预测速度慢
结语
SVM作为一个庞大的算法家族,区区一篇博文无法写尽SVM的点点滴滴,尚有SMO算法,SVM在回归问题的应用没有介绍。另外由本人对SVM应用还不是很多,很多地方理解还不够深入,如有疏漏,请多多指正。
References
- 李航 《统计学习方法》
- Peter Harrington 《机器学习实战》
- Toby Segaran 《集体智慧编程》
- Support vector machines: The linearly separable case
- Andrew Ng CS229 Lecture notes
- A Tutorial on Support Vector Machines for Pattern Recognition
- Karush–Kuhn–Tucker conditions
- SVM - hard or soft margins?
- Introduction to SVM Zhang Liliang
- Lecture 3: SVM dual, kernels and regression
- 支持向量机通俗导论(理解SVM的三层境界)
- A Gentle Introduction to Support Vector Machines in Biomedicine
- Advantages and disadvantages of SVM
- Support Vector and Kernel Machines
-